it is a programming model for processing and generating big data sets with a parallel, distributed algorithm on a cluster
it is a popular framework for processing very large datasets in a distributed setting efficiently, quickly, and in a fault-tolerant manner
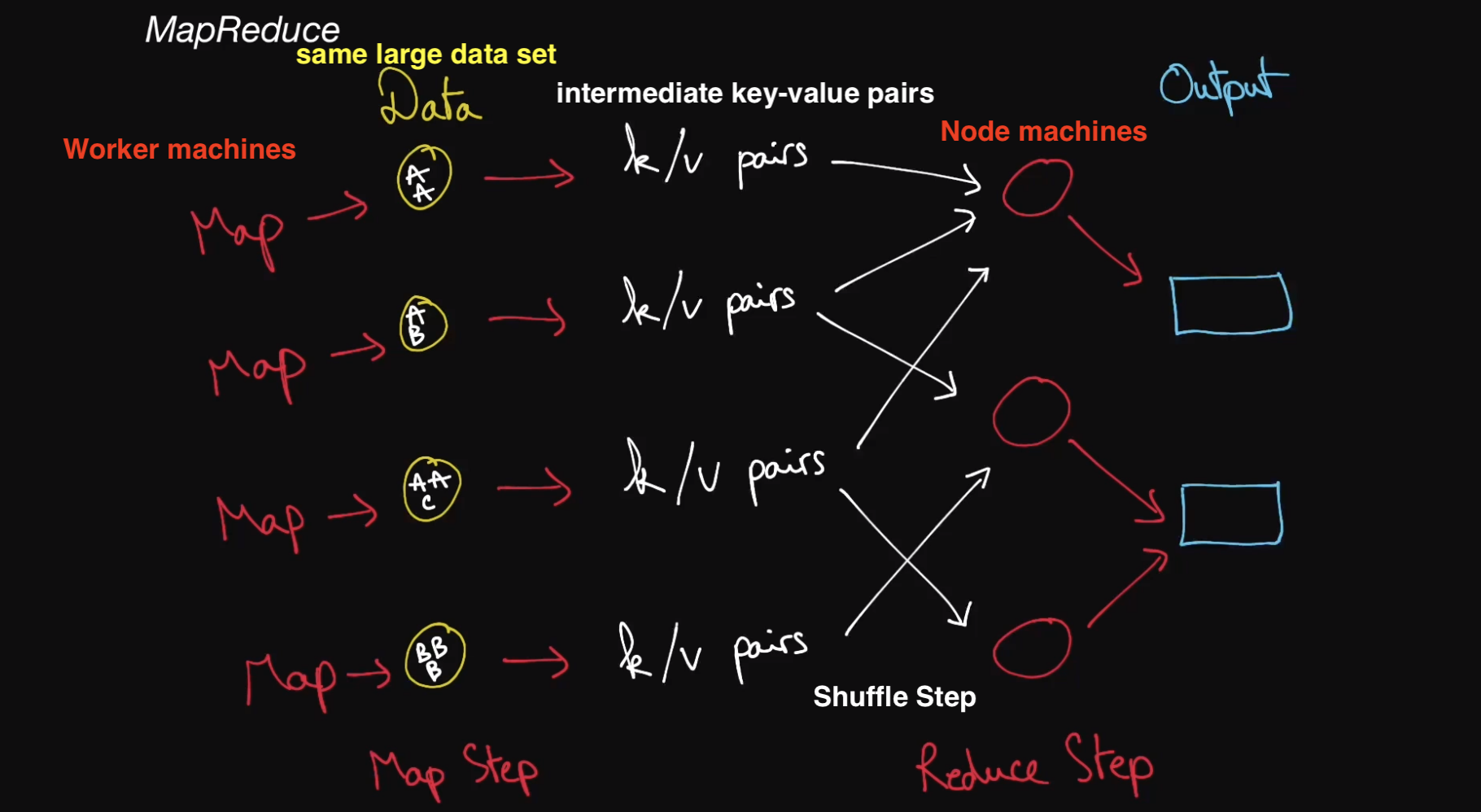
its job is comprised of 3 main steps
the Map step, which runs a map function on the various chunks of the dataset and transforms these chunks into intermediate key-value pairs
these chunks are from the same data sets
the machines used to perform these operations are sometimes referred as worker machines
the Shuffle step, which reorganizes the intermediate key-value pairs such that pairs of the same key are routed to the same machine in the final step
the Reduce step, which runs a reduce function on the newly shuffled key-value pairs and transforms them into more meaningful data
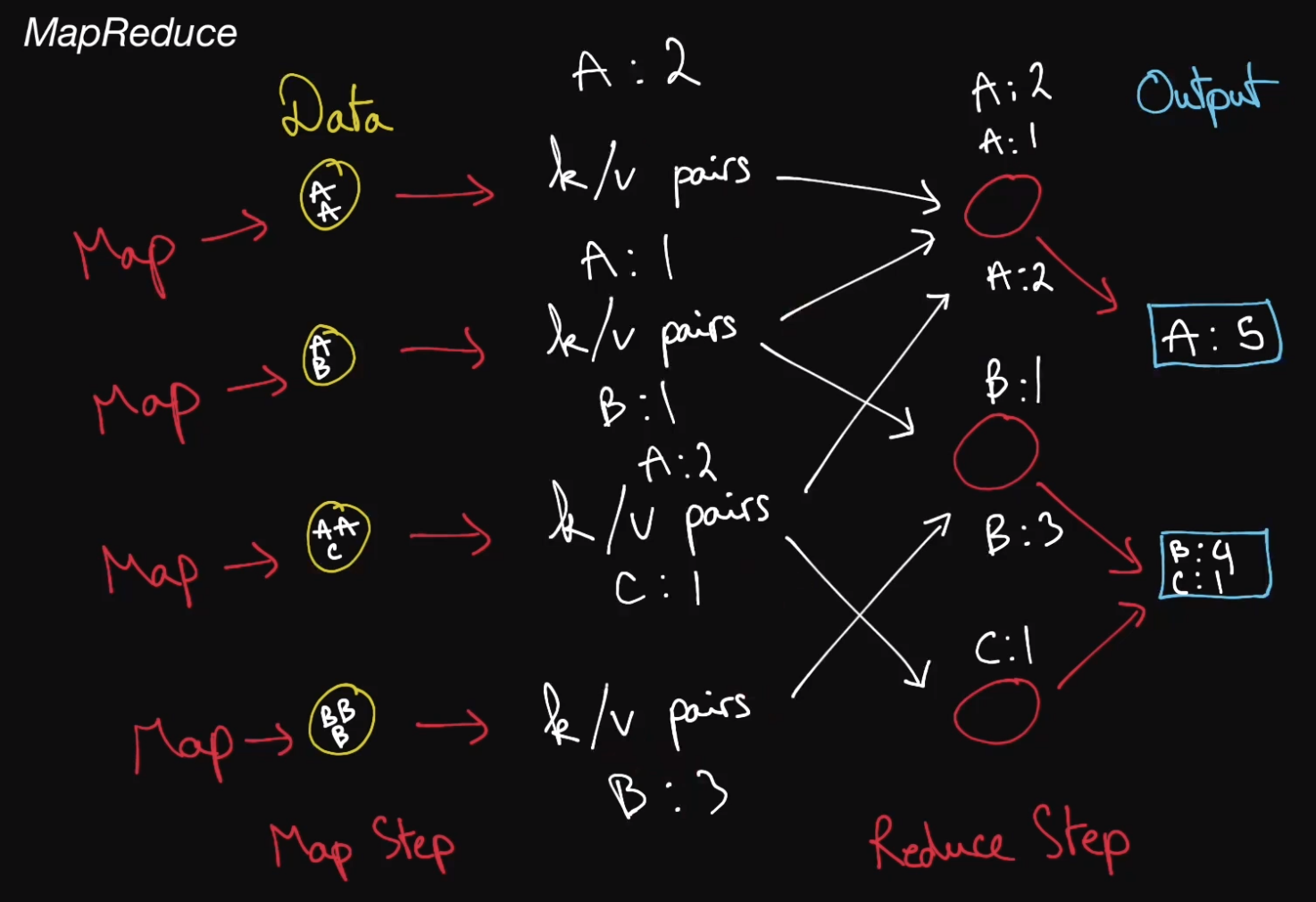
the canonical example of a MapReduce use case is counting the number of occurances of words in a large text file
when dealing with a MapReduce library, engineers and/or system adminstrators only need to worry about the map and reduce functions, as well as their inputs and outputs
all other concerns, including the parallelization of tasks and the fault-tolerance of the MapReduce job, are abstracted away and taken care of by the MapReduce implementation
1st is when dealing with a MapReduce model, we assume that we have a distributed file system
this means that we have some large data set that is split up into chunks
these chunks are likely replicated and spread out across multiple machines in the order of hundreds or thousands of machines
then the distributed file system has some sort of central control plane that is aware of everything going on in the MapReduce job or process
this means that the central control plane knows where all of the chunks of data reside
it knows how to communicate with the various machines that store all of these data
it knows how to communicate with the machines that are gonna be performing the Map opertions (also known as worker machines)
similarily for the Reduce step, it knows how to communicate with the various reduce workers
it knows where your output is gonna live
2nd is that often times because we are dealing with very large datasets, we don't actually want to move the large data set
we want to leave the data set wherever it resides, letting all the chunks of data live on their respective machines
what we do is we have the map functions move to the data and operate on the data locally
3rd is that the intermediate key value pairs structure of the data is very important
important because, when you reduce data values especially data values that come from multiple chunks of the same data set, you are likely looking for some sort of commonality in these various pieces of data
thus some keys would be similar, which can then aggregated together and be reduced into 1 single meaningful value based on that key
4th is that 1 of the main things that this model tries to accomplish is to handle faults and failures
e.g.: if there is a network partition or a machine failure
to handle these a MapReduce job (the central control plane) would re-perform a map or reduce operation where a failure occurred
this will give us new key value pairs, move to the reduce step and we get our final output
this is assuming that the map and reduce function are idempotent
this means that regardless of how many times the map and reduce functions were conducted, the outcome must be the same
5th is that as the engineer or system administrator who is dealing with a MapReduce job
the main thing that you care about is what Map and Reduce function you are gonna specify, and what the various inputs and outputs of those functions is gonna be
an abstraction over a storage medium that defines how to manage data
while there exist many different types of file systems, most follow a hierarchical structure that consists of directories and files, like the Unix file system's structure
typically DFSs take care of the classic availability and replication guarantees that can be tricky to obtain in a distributed system setting
the overarching idea is that files are split into chunks of a certain size (4MB or 64MB)
those chunks are sharded across a large cluster of machines
a central control plane is in charge of deciding where each chunk resides, routing reads to the right nodes, and handling communication between machines
Different DFS implementations have slightly different APIs and semantics, but they achieve the same common goal