Parallel, Concurrent and Multithreading
Parallel Computing Hardware
Sequential vs Parallel computing
sequential
- program is broken down into a sequence of discrete instructions that are executed one after another
- only can execute 1 instruction at any given moment
- limitations
- the time it takes for a sequential program to run is limited by the speed of the processor
- and how fast it can execute that series of instructions
- the time it takes for a sequential program to run is limited by the speed of the processor
parallel
- breaking the tasks for them to be executed simultaneously by different processors
- accomplish a single task faster
- accomplish more tasks in a given time
- the processors has to coordinate with each other as they might be dependent on each other
- does not necessarily means speed will become twice as fast
- if a separate task B requires task A but task A is still processing even though task B is completed
- the entire process will have to wait until task A is completed
- this adds complexity
- does not necessarily means speed will become twice as fast
Parallel computing hardware
-
parallel computing requires parallel hardware
- with multiple processors to execute different parts of a program at the same time
-
different structural types of parallel computers
-
Flynn's Taxonomy: 1 of most widely used systems for classifying multiprocessor architectures
-
Single Instruction Single Data (SISD)
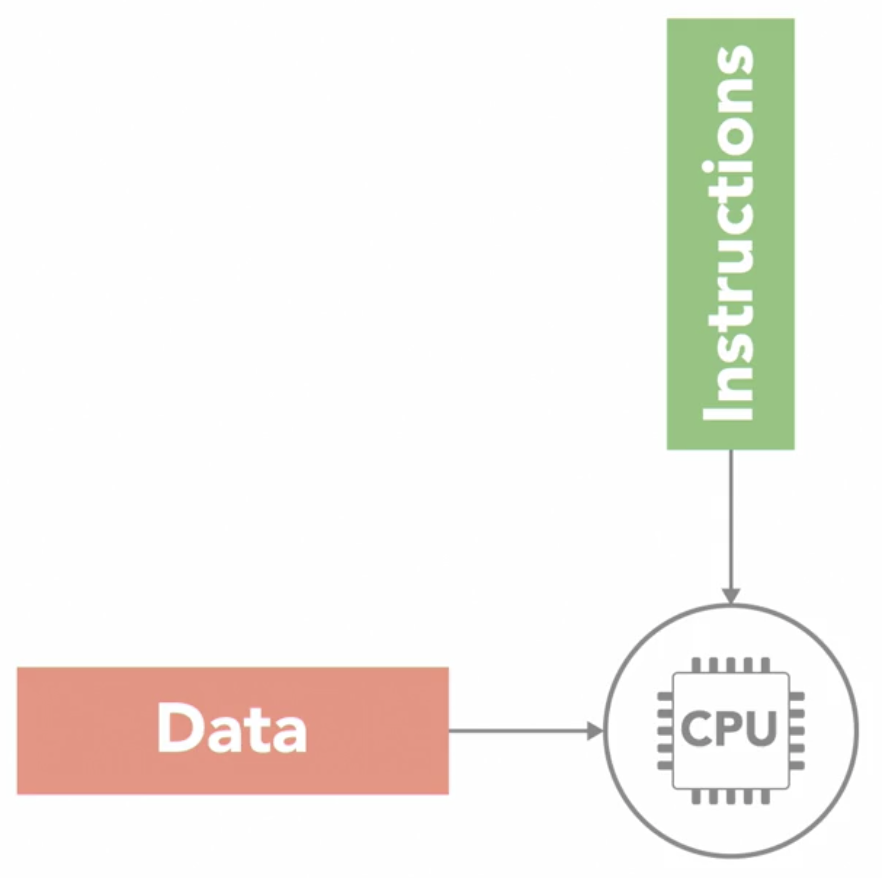
- simplest of the 4 classes
- it is the sequential computer with a single processor unit
- at any given time, can only execute 1 series of instructions and act on 1 element of data at a time
-
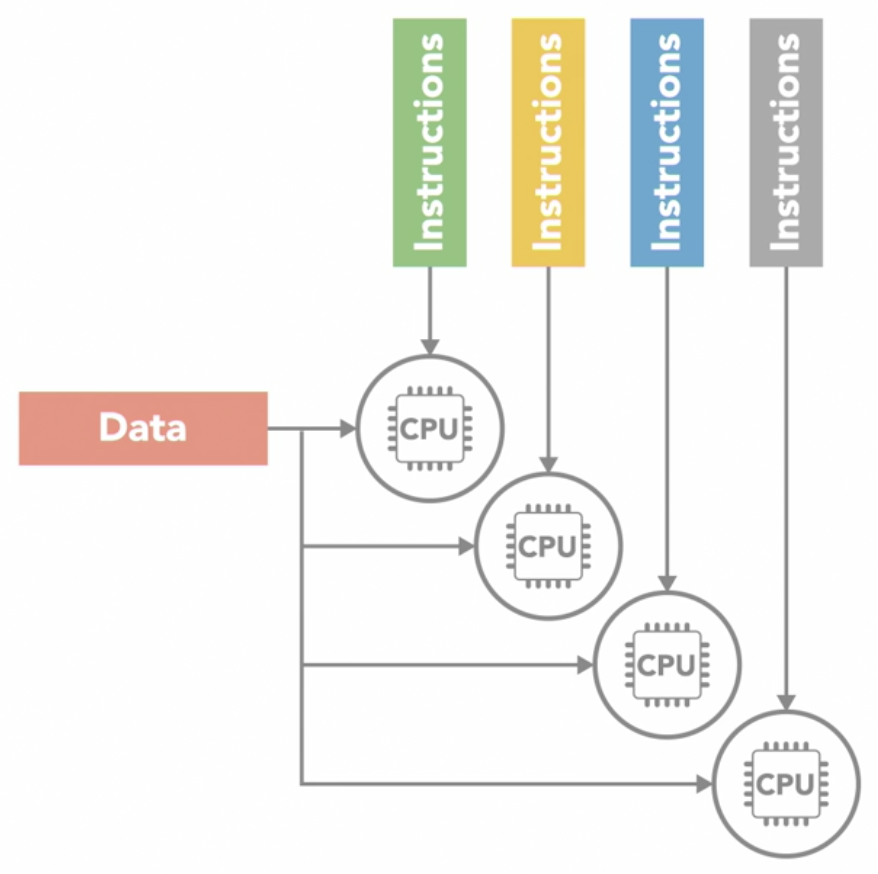
Single Instruction Multiple DATA (SIMD)
- a type of parallel computer with multiple processing units
- all of its processors execute the same instruction at any given time
- but they can operate on different data element
- this type of SIMD architecture is well suited for apps that perform the same handful of operations on a massive set of data elements
- e.g.: image processing
- most modern computers use graphic processing units (GPU) with SIMD instructions to do it
- e.g.: image processing
-
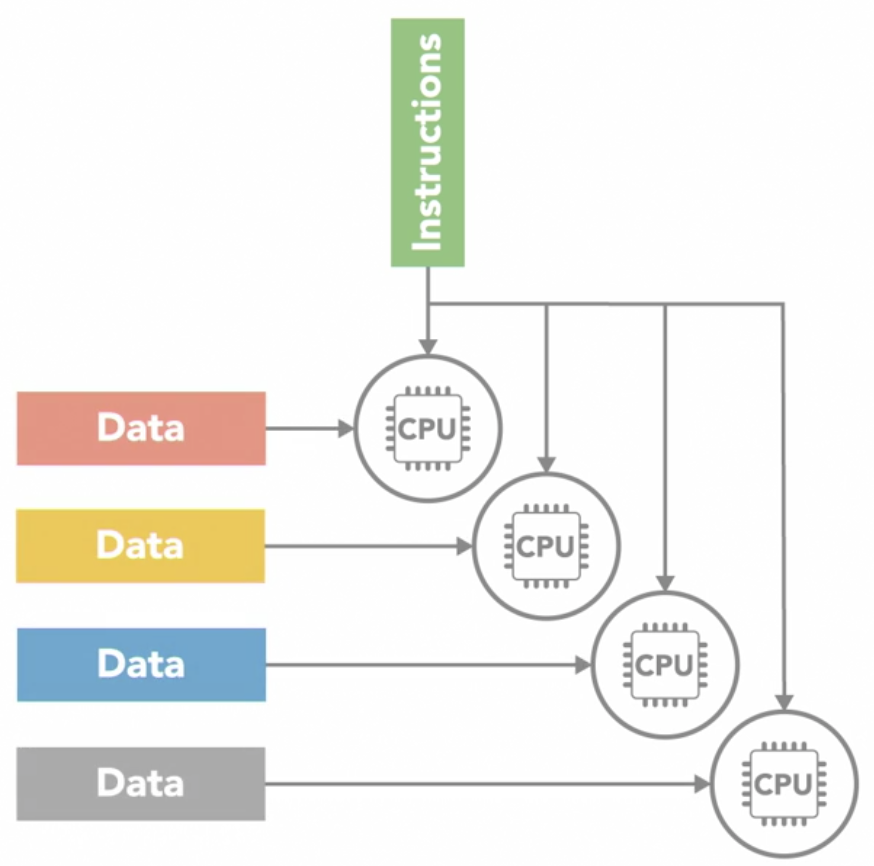
Multiple Instruction Single Data (MISD)
- the opposite of
SIMD - each processing unit independently executes its own separate series of instructions
- however, all of those processors are operating on the same single stream of data
MISDdoesn't make much practical sense, thus its not a commonly used architecture
- the opposite of
-
Multiple Instruction Multiple Data (MIMD)
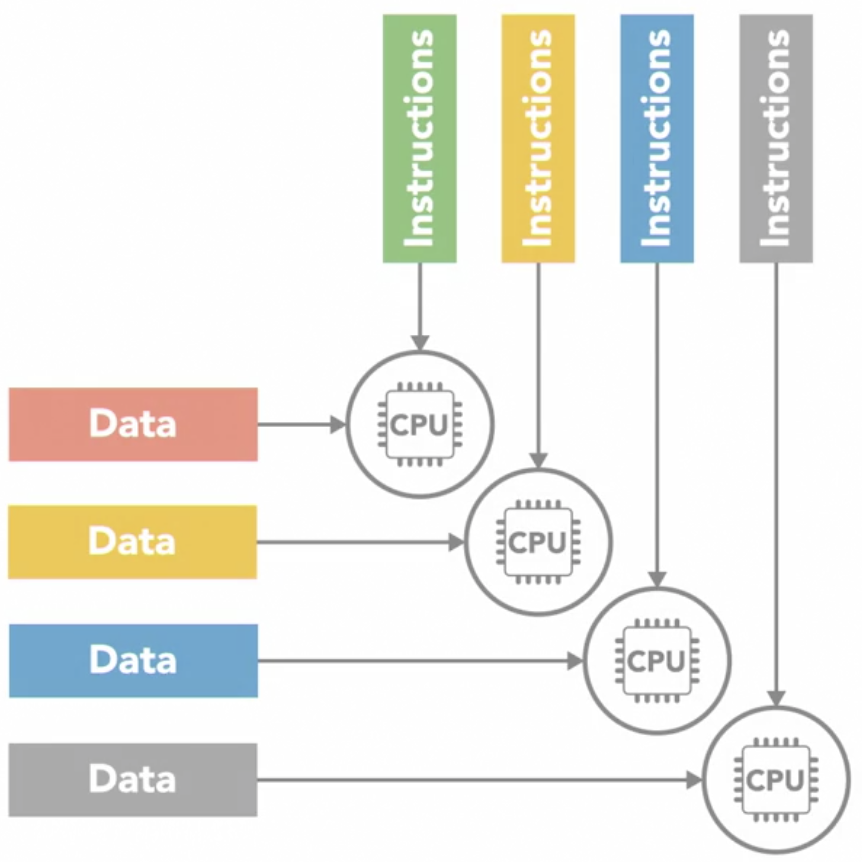
-
every processing unit can be operating on a different set of data
-
it is the most commonly used architecture
-
can find it in multicore PCs, network clusters, supercomputers
-
can be further subdivided into 2 parallel programming models
-
Single Program Multiple Data (SPMD)
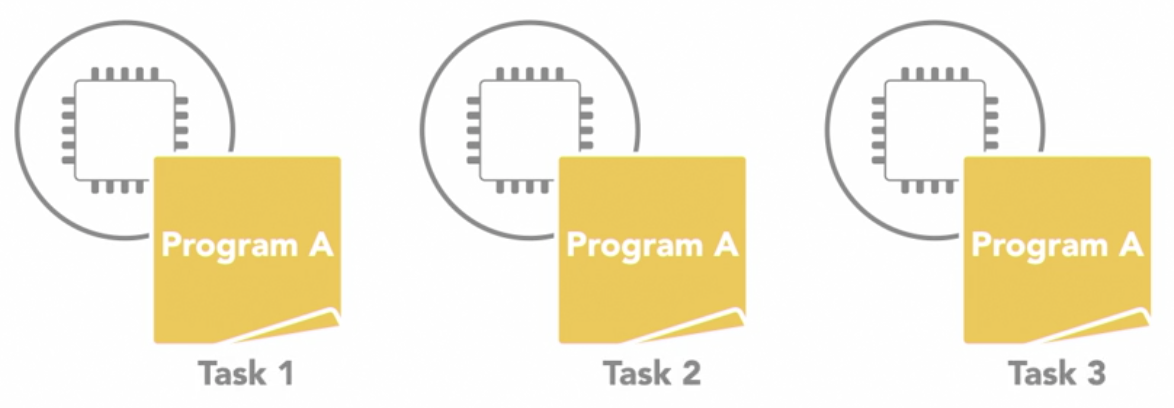
- multiple processing units are executing a copy of the same single program simultaneously
- but each can use different data
- different from
SIMDbecause although each processor is executing the same program- they do not have to be executing the same instruction at the same time
- the processors can run asynchronously
- the program usually includes conditional logic that allows different tasks within the program to only execute specific parts of the overall program
- it is the most common style of parallel programming
- multiple processing units are executing a copy of the same single program simultaneously
-
Multiple Program Multiple Data (MPMD)
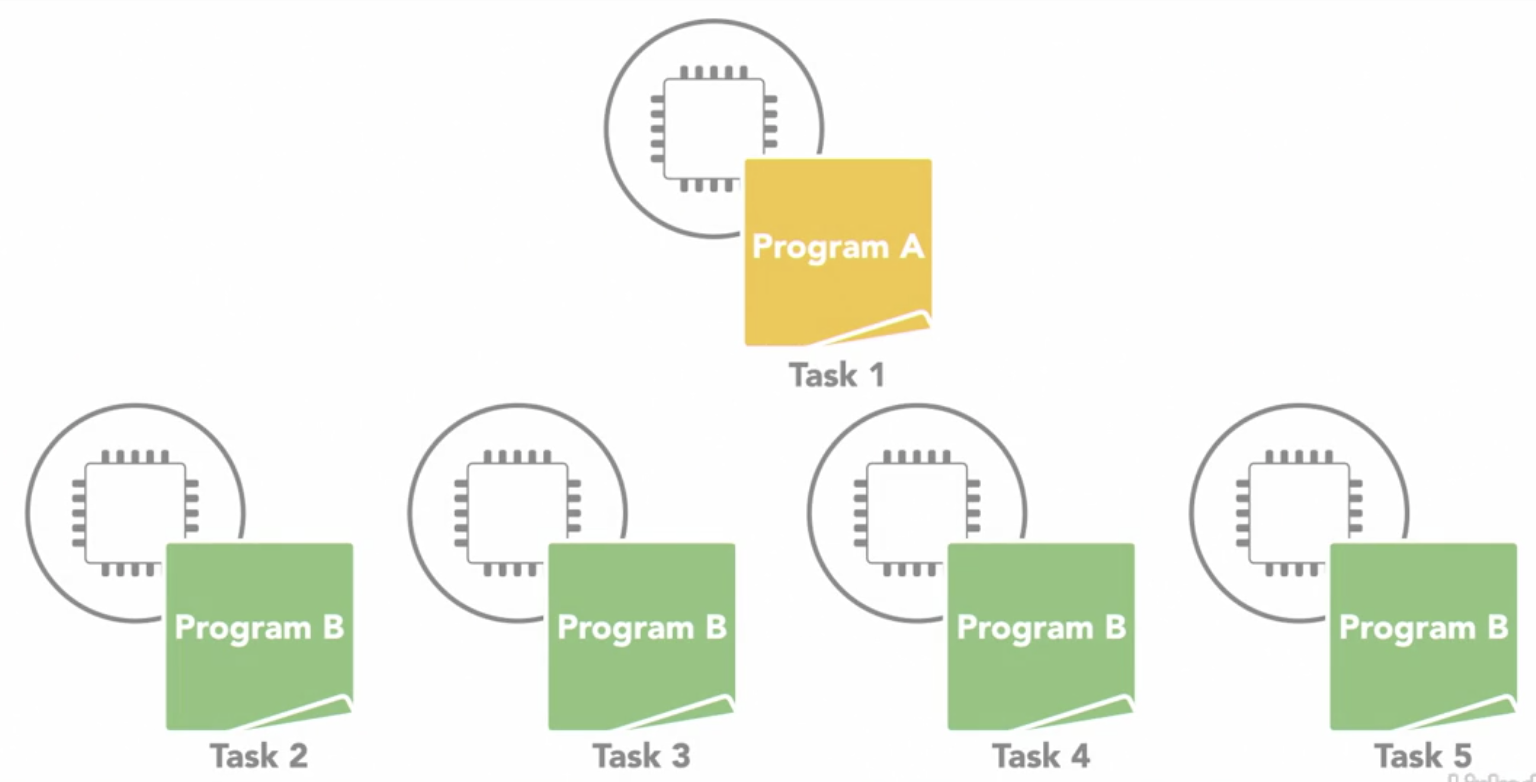
- each processors is executing a different program
- processors can be executing different, independent programs at the same time while also be operating on different data
- typically in this model, 1 processing node will be selected as the host or manager
- which runs 1 program that farms out data to the other nodes running a 2nd program
- those other nodes do their work and return their results to the manager
- it is not as common as
SPMDbut can be useful for some applications that lend themselves to functional decomposition
-
-
-
-
Shared vs distributed memory
-
accessing memory needs to be fast enough to get the instructions and data required in order to be able to make use of more processors
-
computer memory usually operates at a much slower speed than processors
-
when 1 processor is reading or writing to memory, it often prevents any other processors from accessing the same memory element
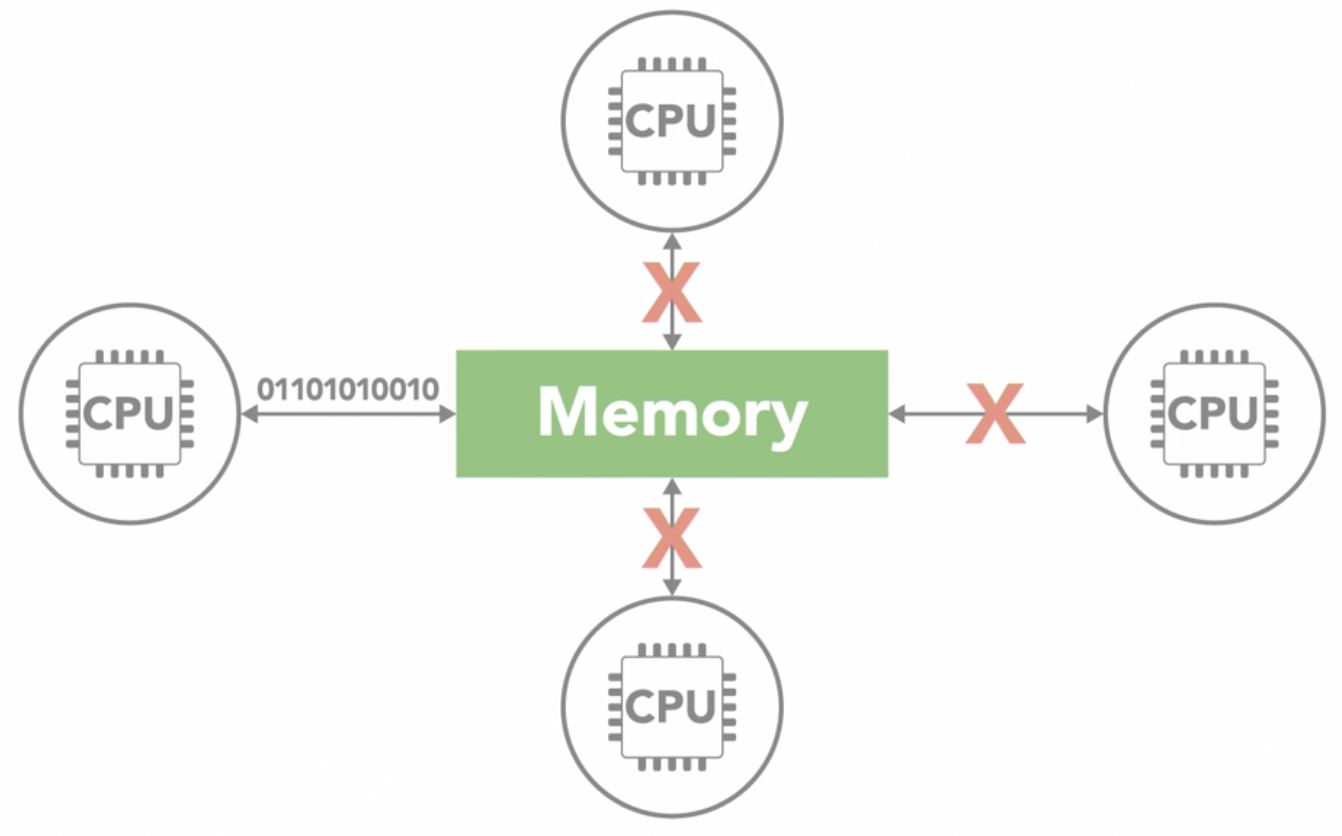
-
there are 2 main memory architectures that exists for parallel computing
-
shared memory
-
all processors have access to the same memory as part of a global address space
-
although each processor operates independently
- if 1 processor changes a memory location, all of the other processor operates will see that change
-
the term shared memory does not mean all data exists on the same physical device
-
it could be spread across a cluster of systems
-
the key is that both of the processors see everything that happens in the shared memory space
-
the shared memory architectures have the advantage of being easier for programming in regards to memory
- because its easier to share data between different parts of a parallel program
-
disadvantage is that they don't often scale well
- adding more processors to a shared memory system will increase traffic on the shared memory bus
- shared memory puts responsibility on the programmer to synchronize memory accesses to ensure correct behavior
-
often classified into 1 of 2 categories, which are based on how the processors are connected to memory and how quickly they can access it
-
Uniform memory access (UMA)
-
all of the processors have equal access to the memory
- means that they can access it equally fast
-
several types of UMA architectures
-
most common is
symmetric multiprocessing system(SMP)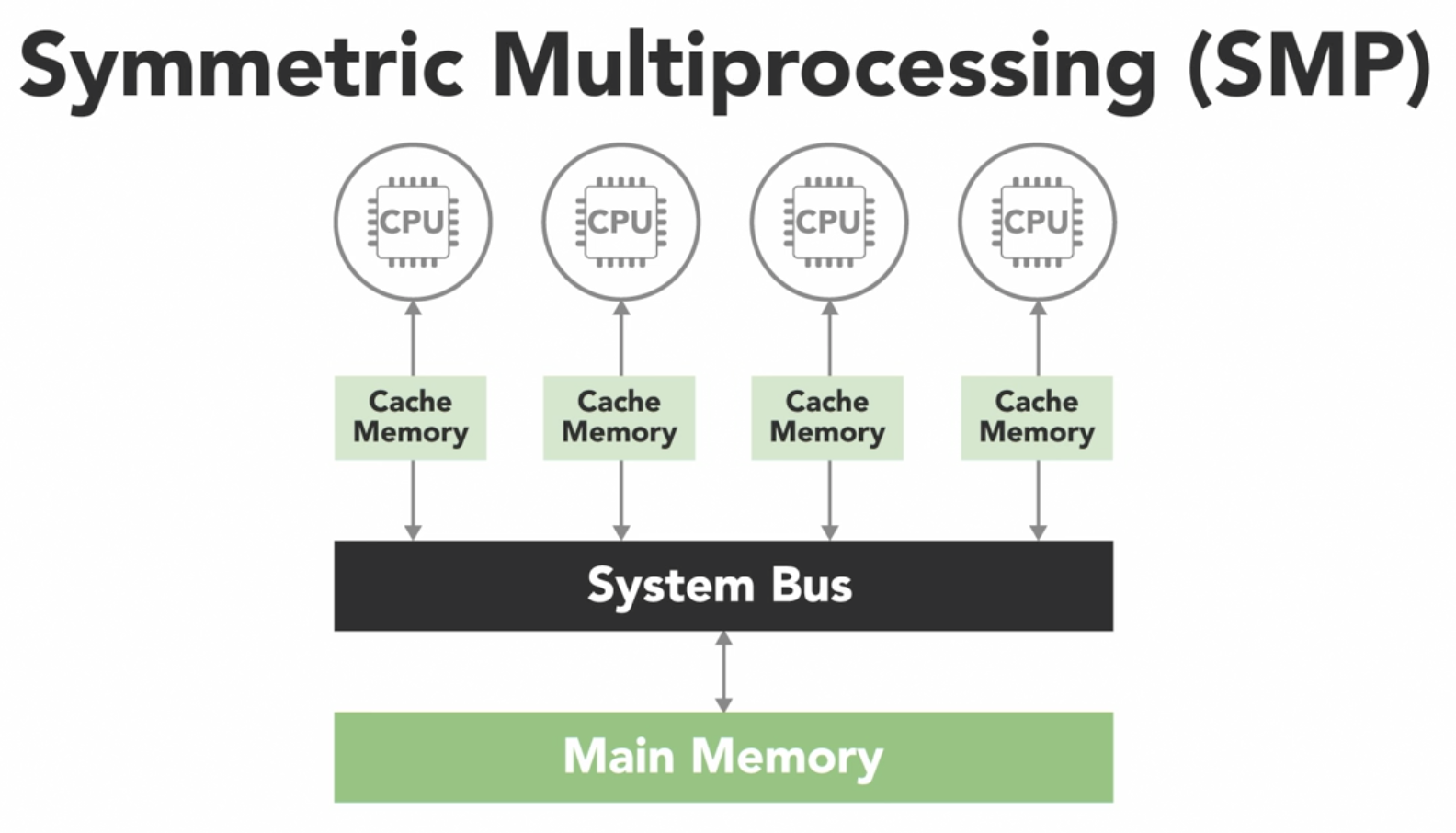
- has 2 or more identical processors which are connected to a single shared memory often through a system bus
- in modern multicore processors, each of the processing cores are treated as a separate processor
- in most modern processors, each core has its own cache
- it is a small and very fast piece of memory that only it can see and it uses it to store data that it's frequently working with
- however, caches introduces the challenge that if 1 processor copies a value from the shared main memory, then makes a change to it in its local cache
- that change needs to be updated back in the shared memory before another processor reads the old value, which is no longer current
- this issue is called
cache coherency - handled by the hardware in multicore processors
-
-
-
Non-uniform memory access (NUMA)
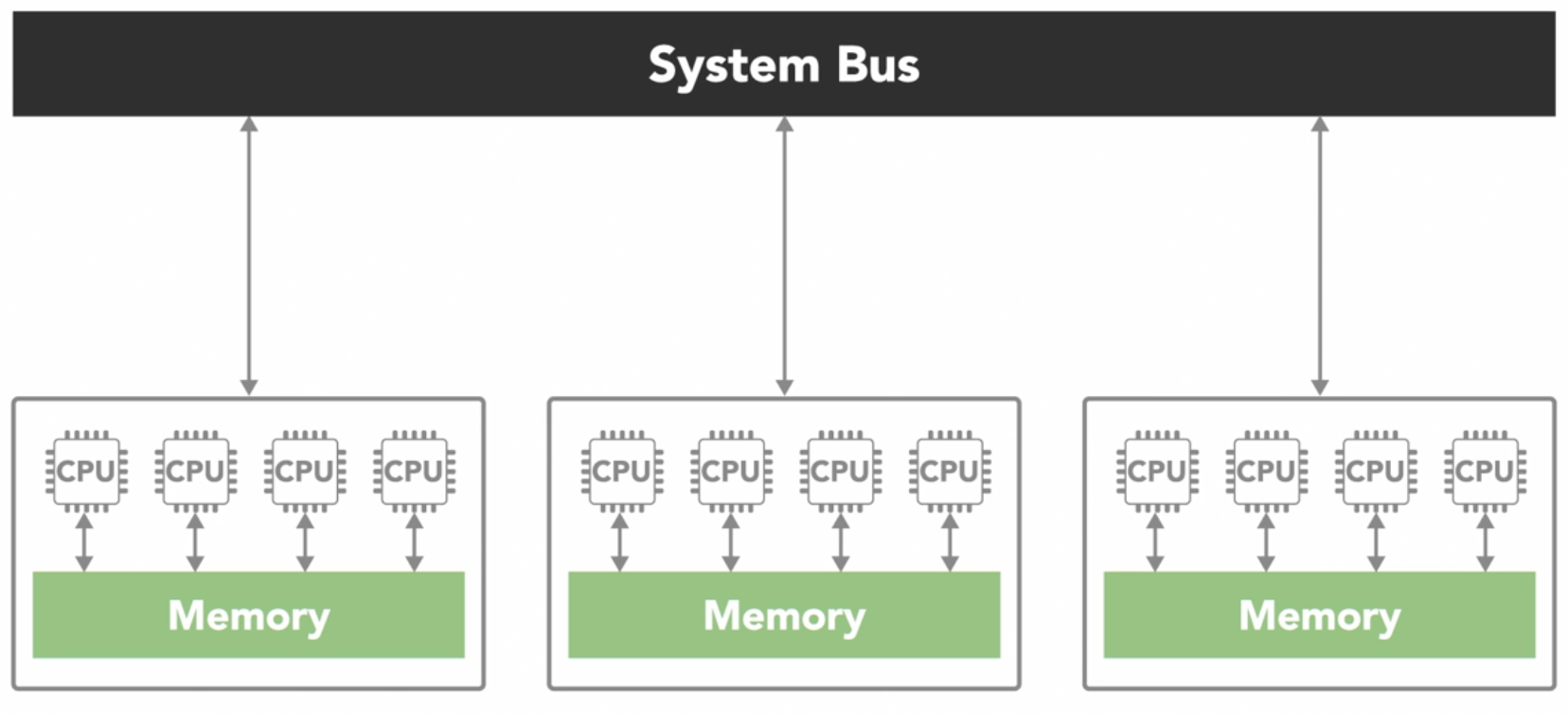
- often made by physically connecting multiple
SMPsystems together - the access is nonuniform because some processors will have quicker access to certain parts of memory than others
- it takes longer to access things over the bus
- overall, every processor can still see everything in memory
- often made by physically connecting multiple
-
-
-
-
distributed memory
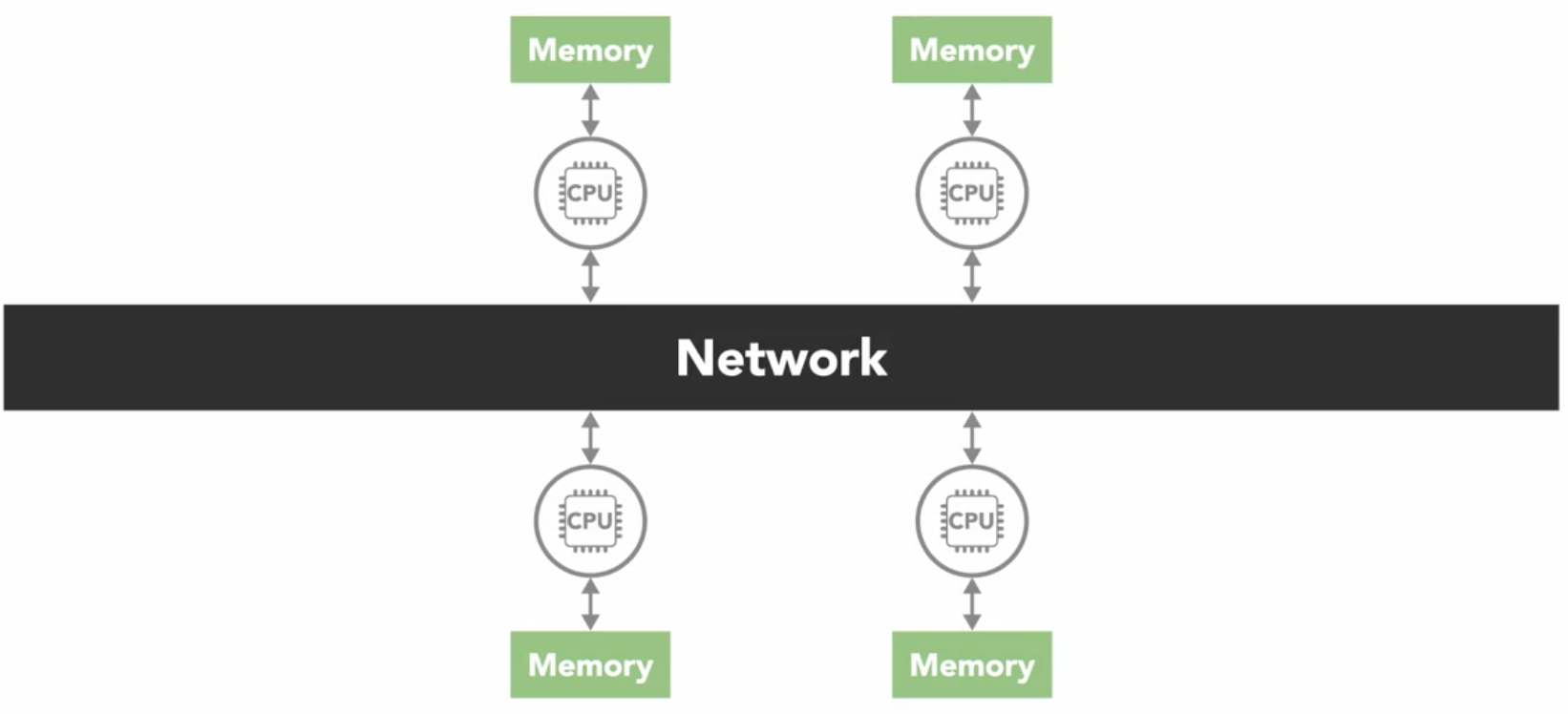
- in a distributed memory system, each processor has its own local memory with its own address space
- concept of a global address space doesn't exist
- all the processors are connected through some sort of network, which can be as simple as
Ethernet - each processor operates independently
- if it makes changes to its local memory, that change is not automatically reflected in the memory of other processors
- it is up to the programmers to explicitly define how and when data is communicated between the nodes in a distributed system
- this is a disadvantage
- advantage of a distributed memory architecture is that its scalable
- when more processors are added to the system, memory also increases
- it makes it cost effector to use commodity, of the shelf computers and networking equipment to build large distributed memory systems
- most supercomputers use some form of distributed memory architecture or a hybrid of distributed and shared memory
-
Threads and Processes
Threads vs process
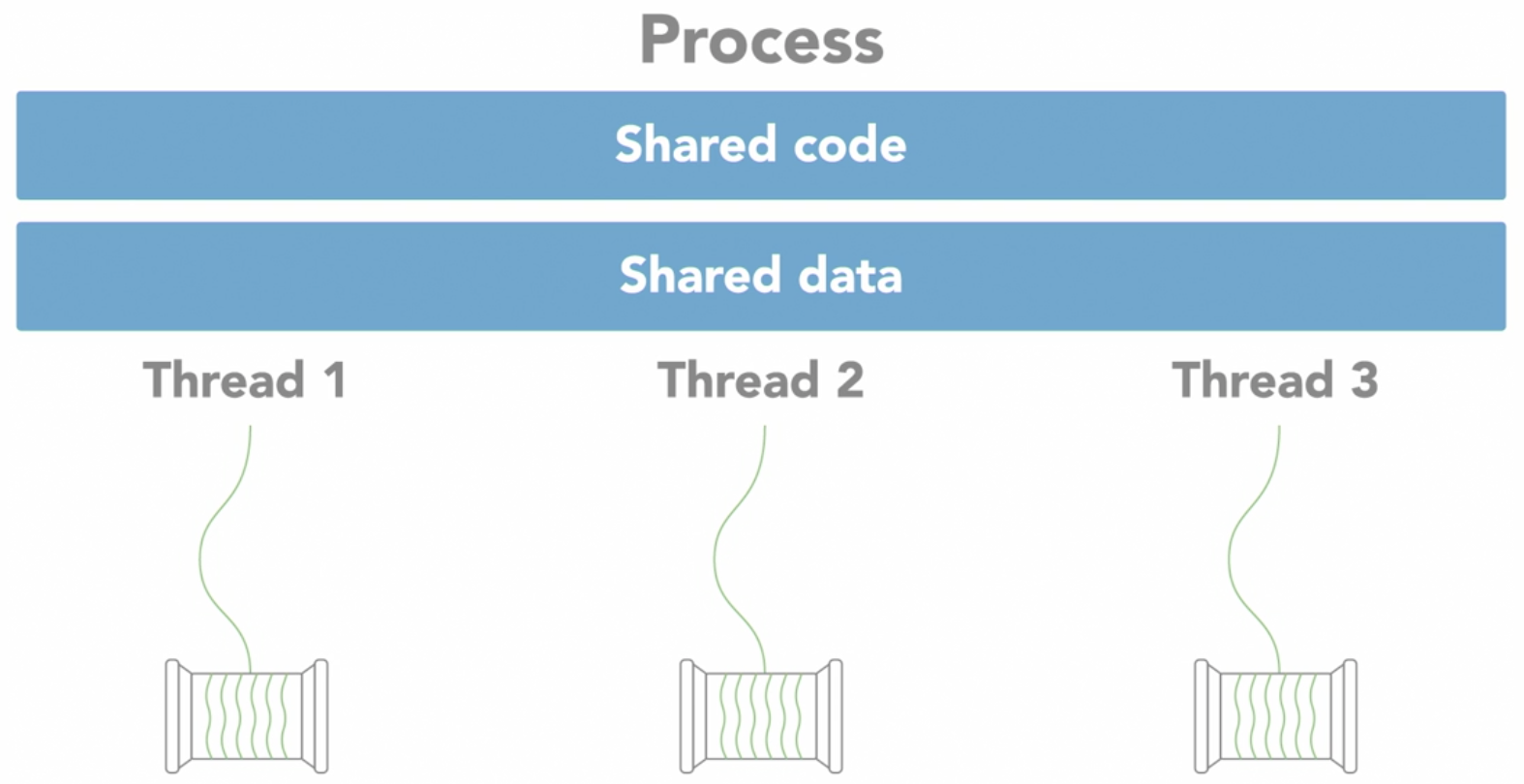
- the concept of 2 people doing the same thing such as cooking
- each person is a thread, while the cooking is the process
- both person work independently contributing to the cooking process
- both have direct access to the same cookbooks containing cooking instructions data
- the ingredients being used represents the data and variables being manipulated
- however, this will cause problems if there are poor coordination between the people (threads)
- process
- it is the instance of the program executing when an application runs on a computer
- the process consists of the program's code, data, and information about its state
- each process is independent and has its own separate address space in memory
- a computer can have hundreds of active processes at once
- the operating system's job is to manage all of these
- sharing resources between separate processes is not as easy as sharing between threads in the same process
- because every process exists in its own address space
- example
- 2 kitchens (processes), 2 person (thread) in each kitchen, working on different recipes (program)
- each kitchen have their own ingredients and you can't access the ingredients from a different kitchen
- 2 kitchens (processes), 2 person (thread) in each kitchen, working on different recipes (program)
- there are ways to communicate and share data between processes, but requires more work than communicating between threads
- threads
- within every process, there are 1 or more smaller sub elements called
threads- these are similar to a tiny processes
- each thread
- is an independent path of execution through the program
- a different sequence of instructions
- can only exist as part of a process
- threads are the basic units that the operating system manages
- it allocates time on the processor to execute them
- threads that belong to the same process share the processes address space
- it gives them access to the same resources in memory including the program's executable code and data
- within every process, there are 1 or more smaller sub elements called
- communication between processes
- e.g.:
- use system provided Inter-Process Communication (IPC) mechanisms like Sockets and pipes
- allocating special inter-process shared memory space
- using remote procedure calls
- e.g.:
- writing parallel programs that use multiple processes working together towards a common goal or using multiple threads within a single process
- which to use depends on what you are doing and the environment it's running
- because implementation of threads and processes differs between operating systems and programming languages
- if the application is going to be distributed across multiple computers, it would be better to separate processes for it
- but as a rule of thumb, if can structure the program to take advantage of multiple threads, stick to using threads than using multiple processes
- because threads are considered lightweight compared to processes, which are more resource intensive
- a thread requires less overhead to create and terminate than a process
- using multiple threads is usually faster for an operating system to switch between executing threads from the same process than to switch between different processes
- which to use depends on what you are doing and the environment it's running
Concurrent vs Parallel execution
- just because a program is structured to have multiple threads or processes does not mean they'll necessarily execute in parallel
| Concurrency | Parallelism |
|---|---|
| Program Structure | Simultaneous Execution |
| Dealing with multiple things at once | Doing multiple things at once |
Concurrency
-
it refers to the ability of an algorithm or program to be broken into parts that can run independently of each other
- they are order independent
- e.g.: in a salad recipe, chopping lettuce, cucumbers, tomatoes etc can be done concurrently by different people and the order is not important
-
Concurrent Execution
-
single processor
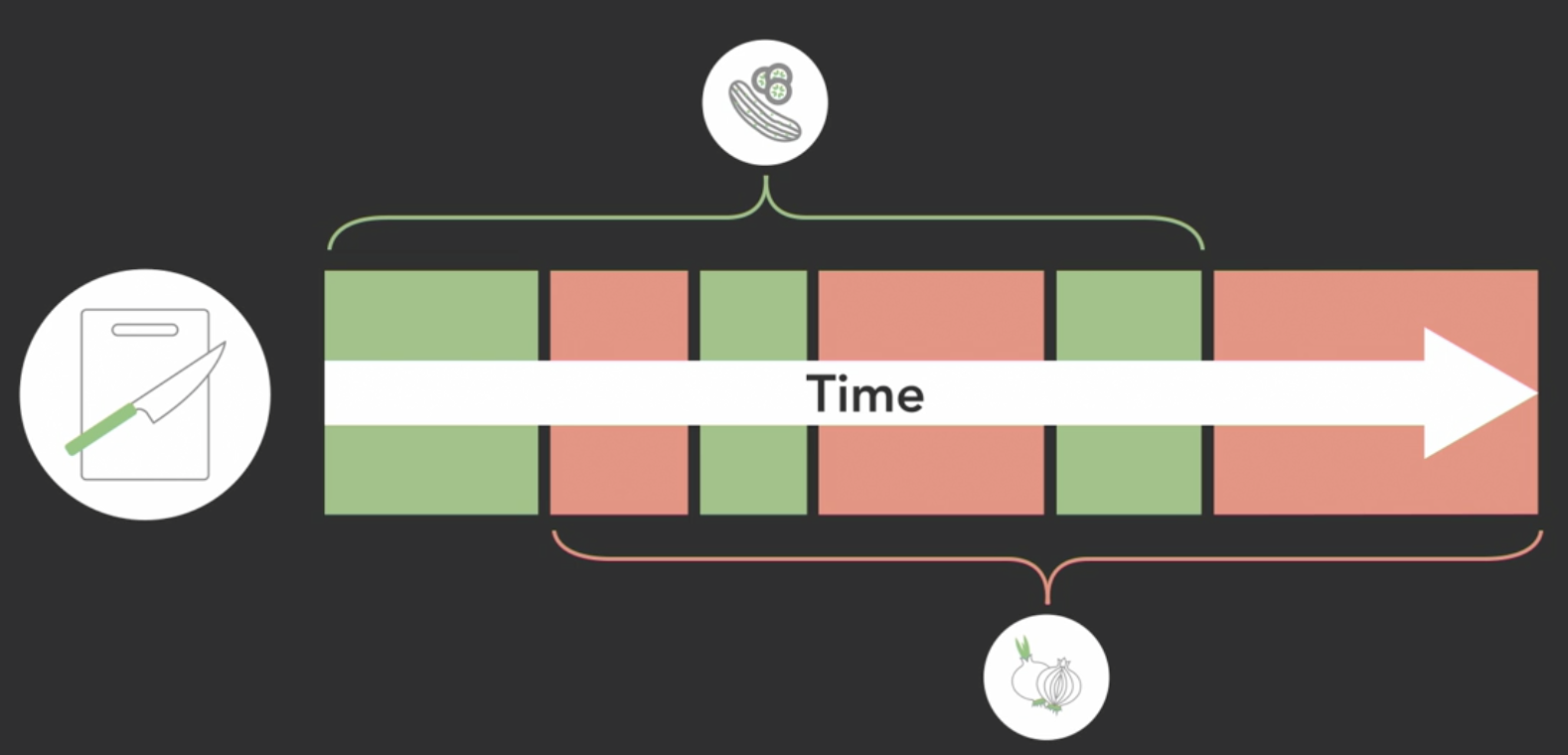
- only 1 task can be executed at any instant in time
- different tasks will be swap and take turns to be executed
- if tasks are swapped frequently
- it creates the illusion that it is executing simultaneously on the single processor, but is not true parallel execution
-
-
Concurrent programming is useful for I/O dependent tasks like graphical user interfaces
- when user clicks a button to execute an operation
- to avoid locking up the user interface until it is completed
- we can run the operation in a separate concurrent thread
- thus leaving the thread that's running the UI free to accept new inputs
- we can run the operation in a separate concurrent thread
Parallel
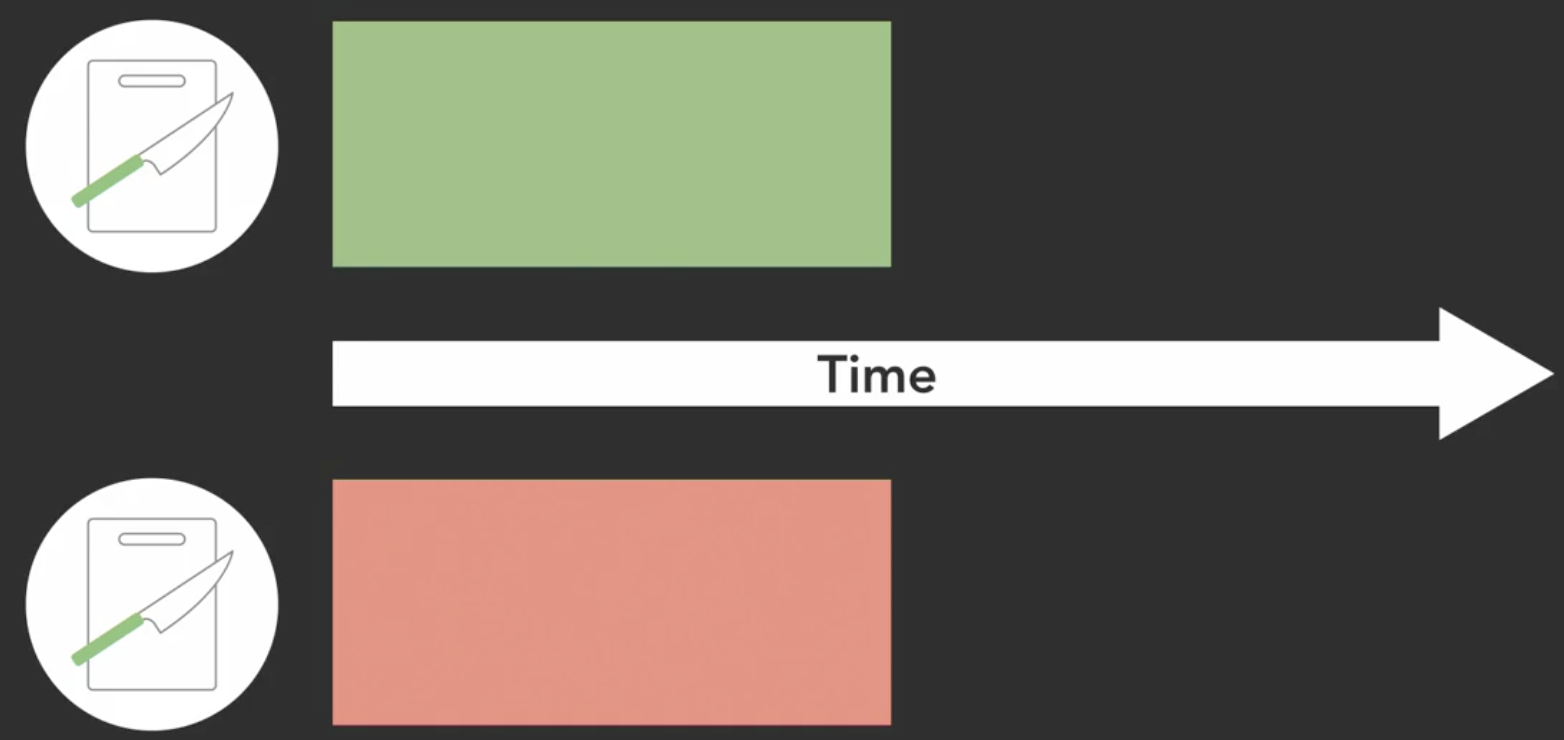
- requires parallel hardware in order to execute in parallel
- types of parallel hardware
- Multi-Core Processors
- used mostly in desktop computers and cellphones
- Graphics Processing Unit
- contains hundreds or thousands of specialized cores working in parallel to make amazing graphics
- Computer Cluster - distribute their processing across multiple systems
- Multi-Core Processors
- types of parallel hardware
- programs may not always benefit from parallel execution
- e.g.: software drivers that handles I/O devices (mouse, keyboard, hard drive)
- they are managed by the operating system as independent things that get executed
- in a multi-core system, the execution of those drivers might get split amongst the available processors
- however, since I/O operations occur infrequently, relative to the speed at which computer operates, nothing is gain from parallel execution
- thus it can run on a single processor without any difference
- e.g.: software drivers that handles I/O devices (mouse, keyboard, hard drive)
- parallel processing becomes useful for computationally intensive tasks
- such as calculating the result of multiplying 2 matrices together
- when large math operations can be divided into independent subparts, executing those parts in parallel on separate processors can speed things up
Execution Scheduling
-
threads don't execute when they want to
-
the Operating System includes a scheduler that controls when different threads and processes get their turn to execute on the CPU
-
the
schedulermakes it possible for multiple programs to run concurrently on a single processor-
when a process is created and ready to run, it gets loaded into memory and placed in the ready queue
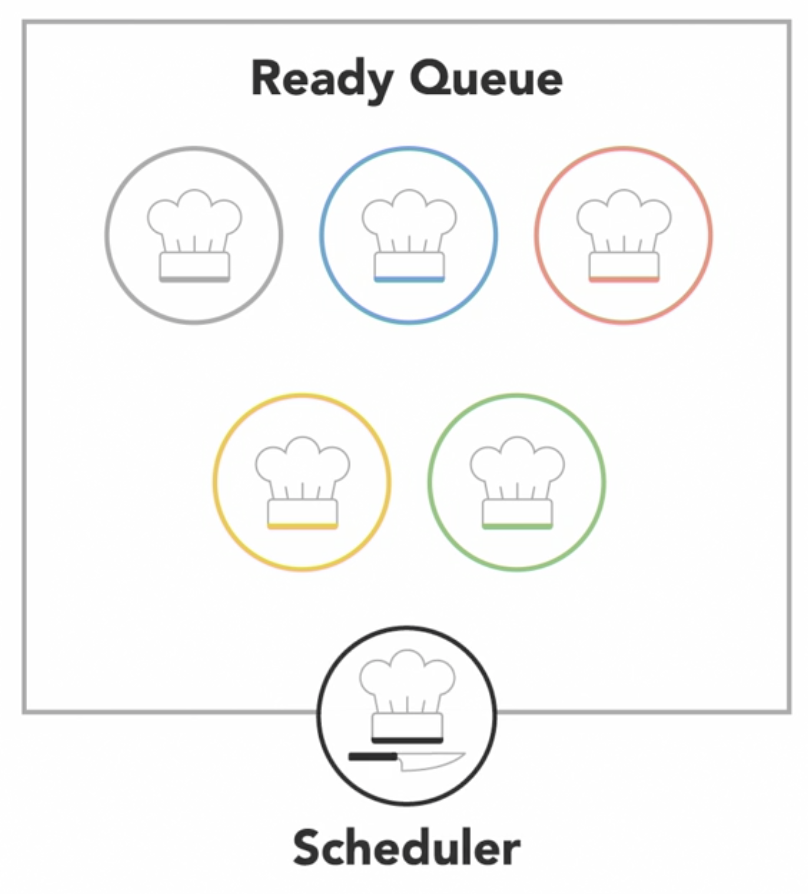
-
the scheduler cycles through the ready processes so that they get a chance to execute on the processor
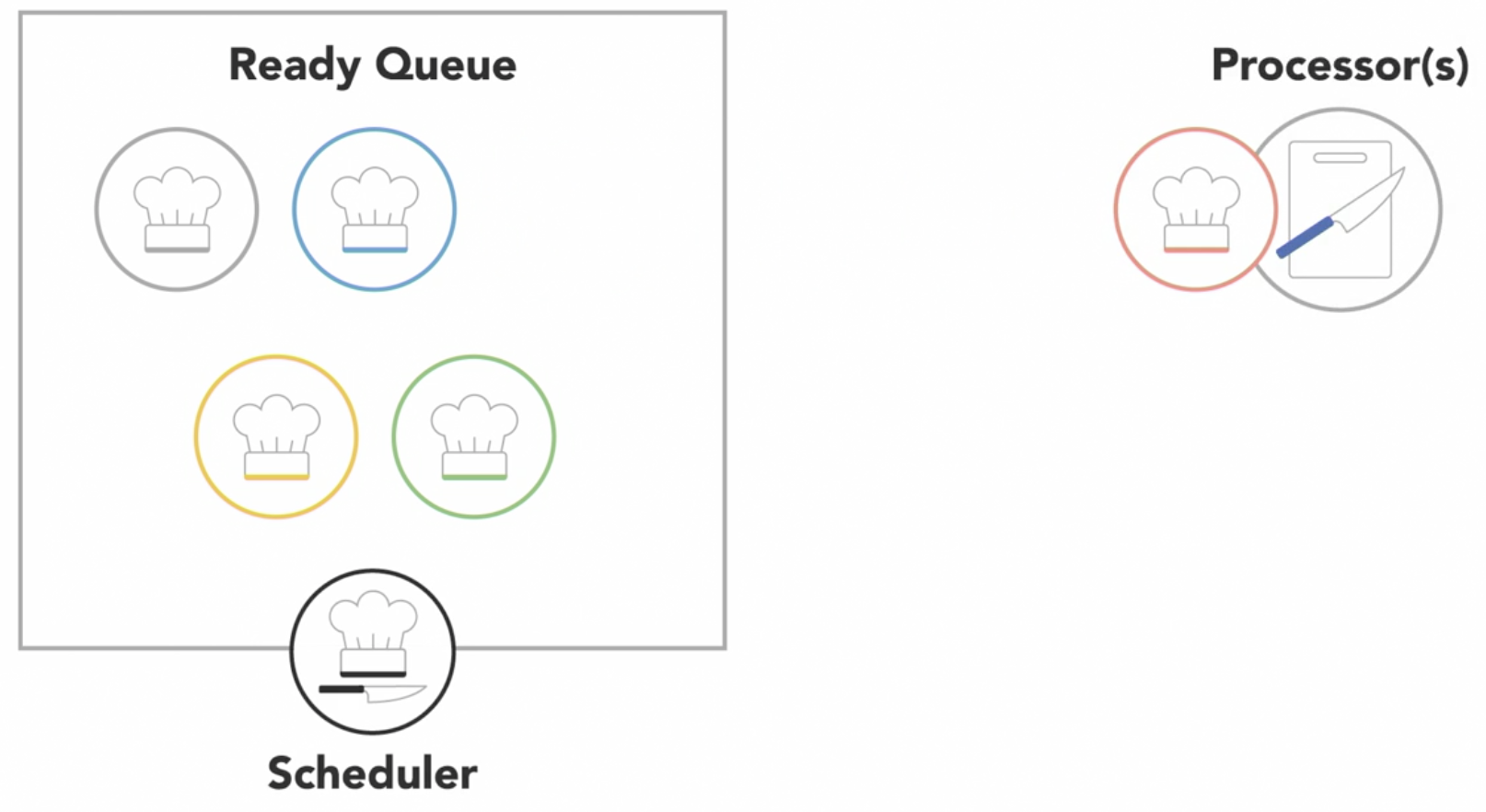
-
if there are multiple processors, the OS will schedule processors to run on each of them to make the most use of the additional resources
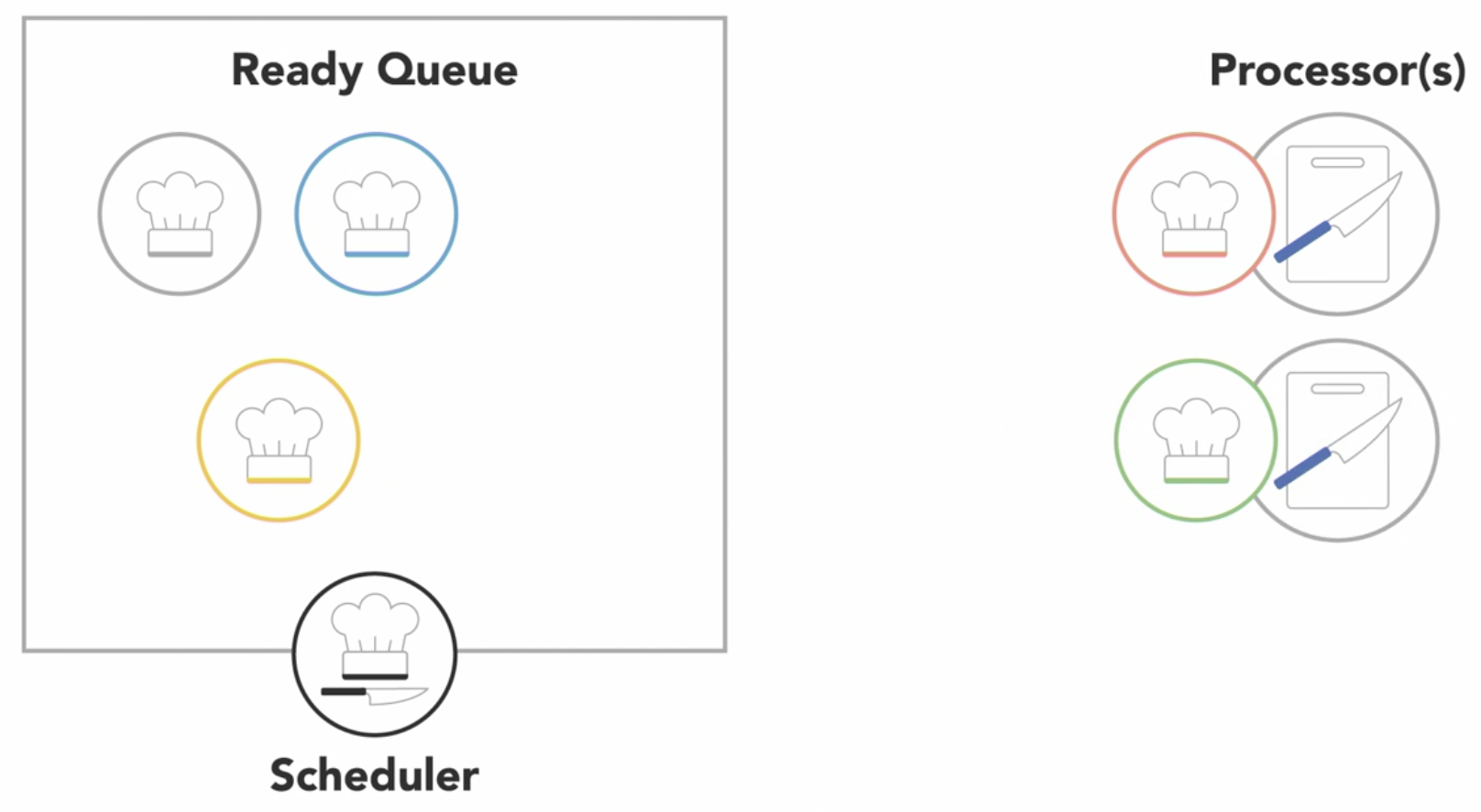
-
a process will run until it finishes, then the scheduler will assign another process to execute on that processor
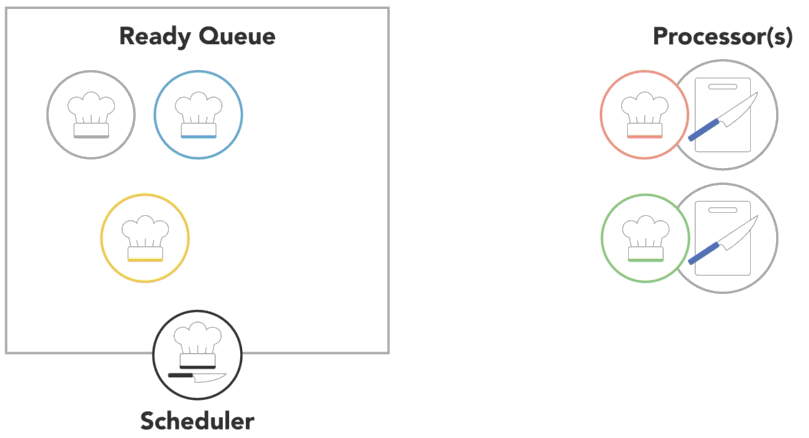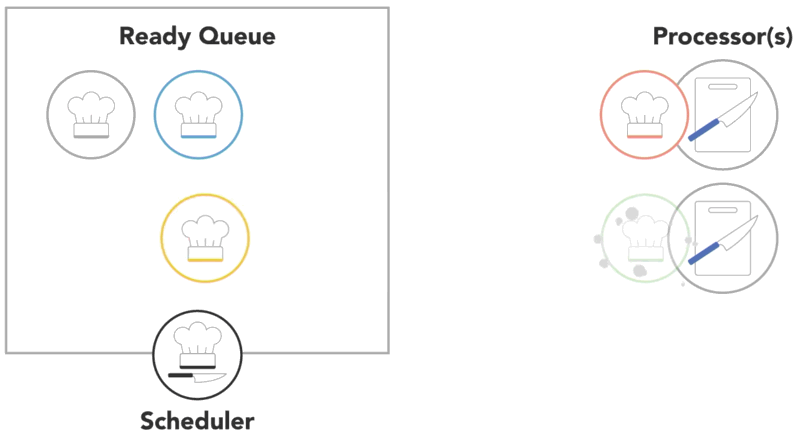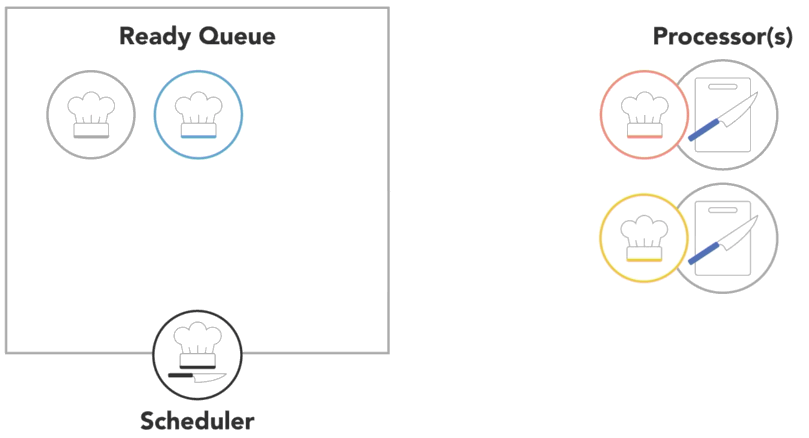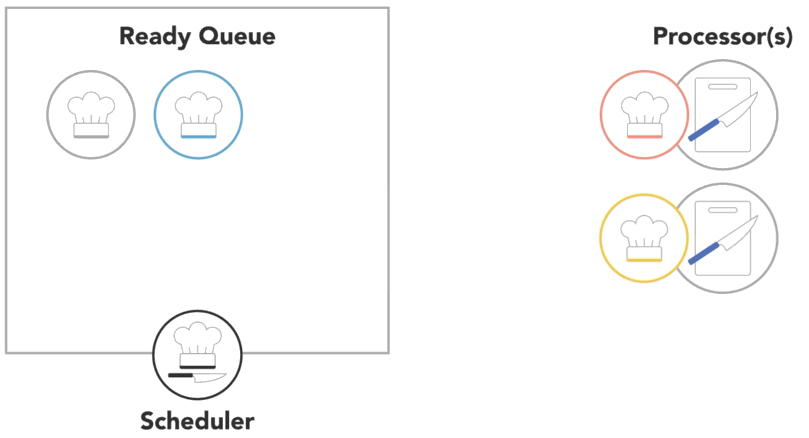
-
or a process might get blocked and have to wait for an I/O event
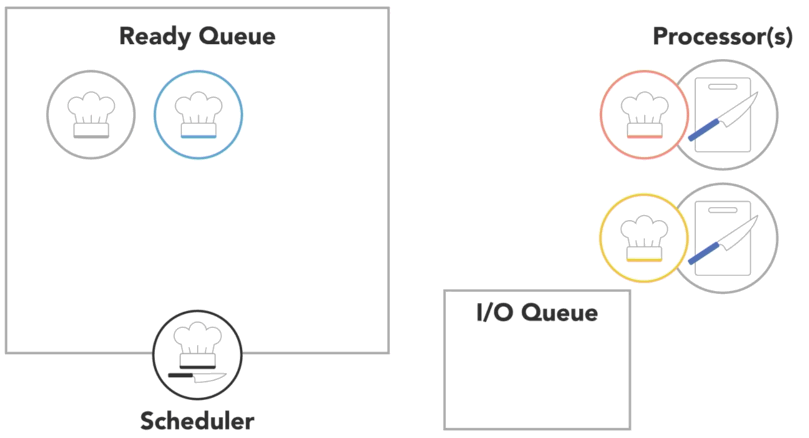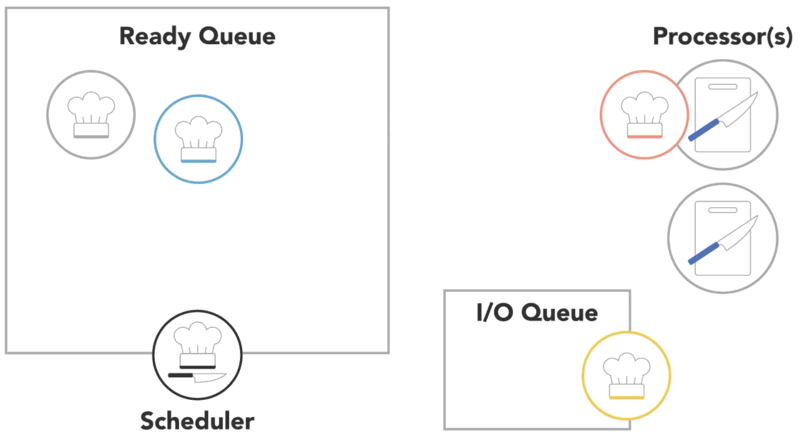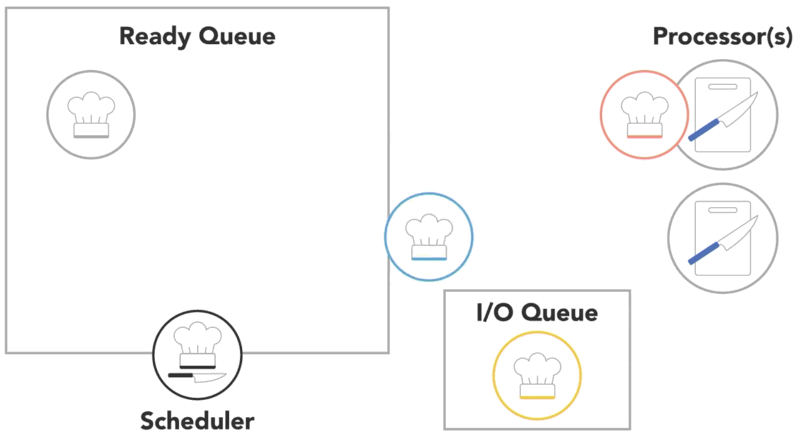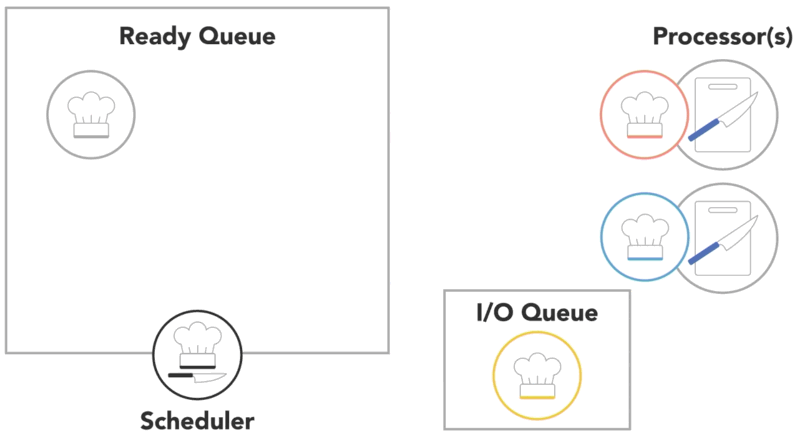
- in this case, it will go into a separate I/O waiting queue so that another process can run
-
or scheduler might determine that a process has spent its fair share of time on the processor and swap it out for another process from the ready queue, also referred to as
context switch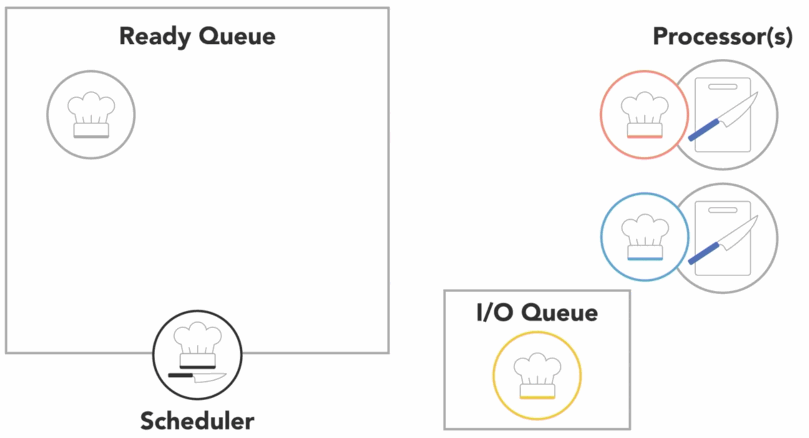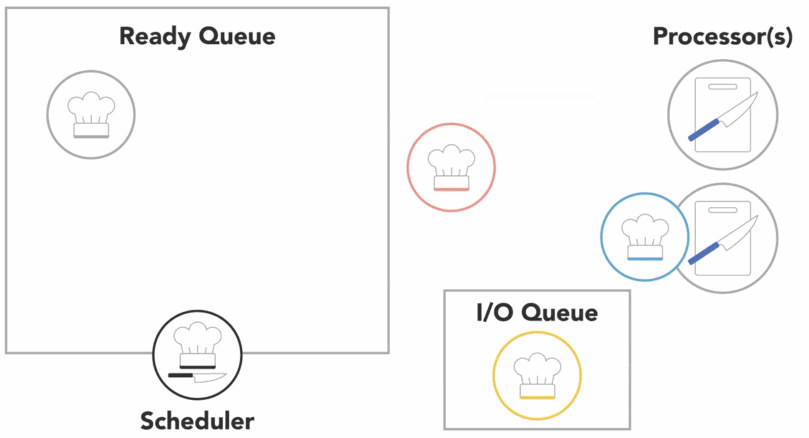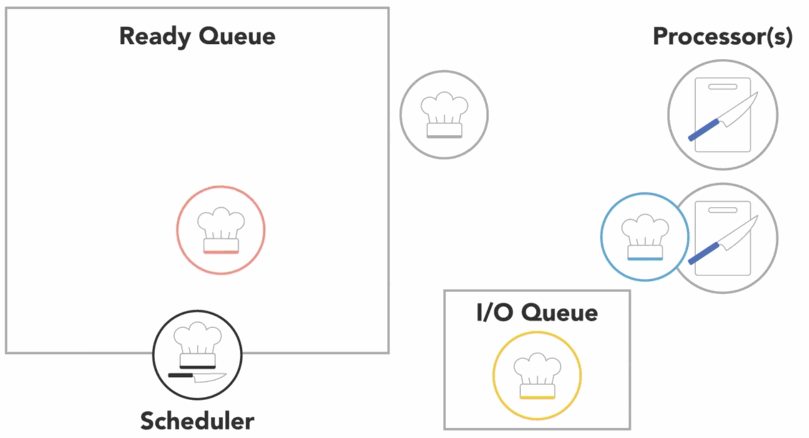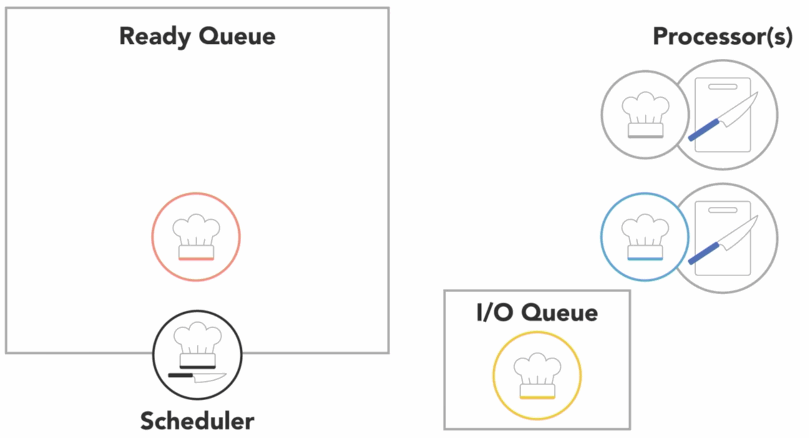
- the OS has to save the state or context of the process that was running so that it can be resumed later
- then it has to load the context of the new process that is about to run
context switchesare not instantaneous- it takes time to save and restore the registers and memory state
- thus the scheduler needs a strategy for how frequently it switches between processes
Scheduling Algorithms- First come, first served
- Shortest job next
- Priority
- Shortest remaining time
- Round-robin
- Multiple level queues
Preemptive Algorithms- a running low priority task might pause or preempt when a higher priority task enters the ready state
Non-preemptive Algorithms- once a process enters the ready state, it'll be allowed to run for its allotted time
-
-
-
Which scheduling algorithm is used by the OS depends which of the following scheduling goals is required
- maximize throughput
- maximize fairness
- minimize wait time
- minimize latency
-
we might not have any control over when the parts of the program gets executed as it is often handled under the hood by the OS